

¿Qué es el AutoML? ¿Qué tareas facilita? ¿Qué limitaciones tiene? Introducción a las tecnologías Automated Machine Learning a partir del análisis de todas las fases de un proyecto de Machine Learning en producción.
Según las estimaciones realizadas sobre el volumen de datos/información creada, capturada, copiada, y consumida en el mundo, en el año 2025 se superarán los 180 zettabytes.
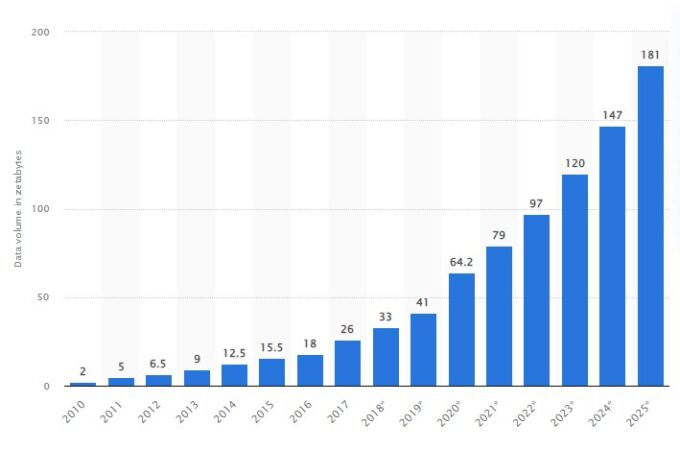
Este aumento en la cantidad de datos, junto a la alta demanda de proyectos de Machine Learning (ML), ha sido el impulsor definitivo del desarrollo de herramientas de automatización de procesos de Machine Learning (AutoML).
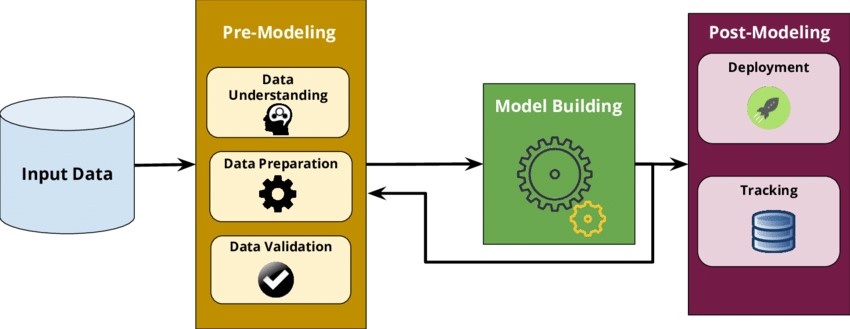
Para entender bien en qué consiste AutoML (Automated Machine Learning), hay que conocer bien las fases de un proyecto de Machine Learning puesto en producción (ver la figura más abajo). La primera de ellas incluye el entendimiento y la preparación de los datos que se introducen en el modelo. La segunda fase es la construcción del modelo y la última es su despliegue para poder realizar las predicciones. Esta última fase debe incluir un sistema de monitorización que permita disparar alarmas y realizar un seguimiento continuo sobre el rendimiento del modelo.
AutoML (Automated Machine Learning) es un sistema, proceso o aplicación que permite automatizar el proceso completo (end-to-end) de un proyecto ML. El principal objetivo de esta automatización es eliminar la interacción humana de todo el proceso. El ideal al que aspiran estas herramientas consiste en subir un fichero de datos, pulsar un botón y obtener resultados perfectos para el problema que pretendemos resolver. El usuario de la plataforma sólo necesita especificar lo que quiere realizar, y el sistema debe saber como computarlo para obtener los mejores resultados. Este objetivo es muy ambicioso ya que exige automatizar muchos procesos que requieren de conocimiento previo del problema que se quiere resolver (incluso si es ML una aproximación adecuada a ese problema). Obviamente, las herramientas de AutoML existentes quedan aún lejos de ese objetivo: no existe ninguna capaz de automatizar todos los tipos de algoritmos de ML, se adaptan mejor a resolver problemas de Ciencia de Datos estándar (clasificación, regresión, etc.) pero necesitan dar un salto de calidad en los problemas de aprendizaje no supervisado.
En muchas ocasiones los sistemas AutoML son confundidos con el proceso conocido como CASH (Combined Algorithm Selection and Hyperparameter Optimization) que consiste en una librería de optimización de los algoritmos de ML (se corresponde con la caja verde de la imagen superior), capaz de realizar las siguientes operaciones:
• Transformaciones.
• Imputación de los missing values.
• Selección de variables.
• Selección de hiperparámetros.
Este tipo de herramientas son clave para desarrollar buenos modelos predictivos (un ejemplo de librería CASH es Auto-WEKA). Sin embargo, un sistema AutoML ofrece mucho más.
Fases de ML utilizando una herramienta de AutoML
Antes de comenzar con un proyecto de ML es necesario responder a tres preguntas:
• ¿Qué problema se quiere resolver?
• ¿Qué se quiere conseguir con la solución?
• ¿Es necesario ML para resolverlo?
Estas preguntas son clave antes de comenzar cualquier proyecto de ML ya que muchos problemas se pueden resolver con un buen análisis de datos, soluciones estadísticas, o son realmente problemas de optimización (analítica prescriptiva, y no predictiva).
Una vez el problema ha sido confirmado como un problema resoluble con ML, se necesitan datos. Es necesario identificar qué datos se necesitan (porque son relevantes para el problema, que es algo que necesita conocimiento del negocio), y la manera en la que se van a conseguir para alimentar a los modelos. Hará falta resolver el acceso a sistemas de información no siempre fáciles de integrar, o a fuentes externas, muchas veces con datos incompletos o no preparados para el objetivo de nuestro proyecto ML. Este paso es muy importante y suele consumir mucho tiempo de la implementación. Al menos requerirá de varios procesos ETL, de mayor o menor complejidad.
En la siguiente imagen se muestra el flujo de un proyecto de ML en producción utilizando un sistema AutoML. Tal y como se ha descrito anteriormente, en los dos pasos iniciales es necesaria la intervención de un experto que interprete bien el problema y sea capaz de conseguir limpiar y procesar los datos que permitan la modelización del problema, tarea que está fuera del alcance de los sistemas de AutoML.
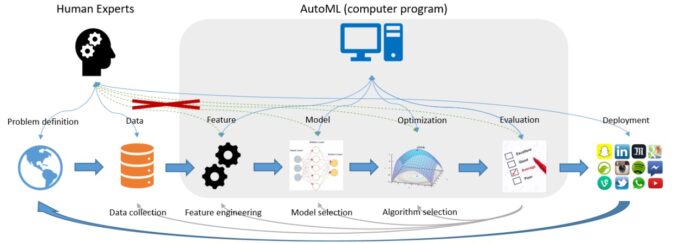
Sólo unas pocas herramientas de AutoML (por ejemplo, DataRobot, H20 Driverless AI) realizan la tarea conocida como feature engineering (ingeniería de características), que consiste en utilizar el conocimiento del terreno para seleccionar y transformar las variables más relevantes de los datos brutos antes de construir el modelo predictivo. Por lo tanto, es necesario el conocimiento del problema que aporta un experto en el dominio, para afinar los resultados en función del caso de uso. En esta fase del proceso, su concurso es mucho más destacable cuando los datos de entrada son más complejos que simples datos tabulares (por ejemplo, texto en lenguaje natural, imágenes, etc.), algo relativamente habitual en muchos escenarios.
Una vez los datos han sido preparados, el sistema AutoML lanza el entrenamiento de modelos, con solo pulsar un botón se pueden entrenar muchos modelos en paralelo en la nube o en el servidor on-premise del que se disponga. Tras haberse finalizado el entrenamiento de los modelos, las herramientas de AutoML realizan la evaluación de los modelos, y permiten la intervención del usuario experto para elegir el mejor modelo a desplegar. Las herramientas AutoML poseen una larga colección de tipos de modelo a aplicar, y en la mayoría de las ocasiones los mejores resultados son obtenidos con modelos más complejos. Estos modelos suelen ser complicados de interpretar (aunque las herramientas AutoML facilitan parcialmente esa interpretación), necesitan mucho tiempo de computación para ser entrenados y para realizar las predicciones y, además, son difíciles de mantener sin el apoyo de expertos en Ciencia de Datos.
Cuando se ha seleccionado el modelo, es momento de desplegarlo para que pueda ser accesible desde diferentes procesos de negocio. Las herramientas AutoML posibilitan este despliegue de los modelos para la obtención de predicciones y, además, poseen un sistema de monitorización de los modelos desplegados para hacer un seguimiento y un análisis de su rendimiento.
Por último, no debemos olvidar la parte más valiosa de todo el proceso ML: la toma de decisiones basada en los datos obtenidos. Para esta parte hay algunas herramientas de AutoML que aportan valor, pero nuevamente es necesaria la intervención humana para la definición de unas reglas que se adecúen al rendimiento del modelo.
En suma, las herramientas de AutoML facilitan mucho este tipo de tareas y tienen guías de buenas prácticas que correctamente aplicadas reducen mucho el tiempo de desarrollo de estos proyectos, pero es necesario tener un amplio conocimiento del problema y de Ciencia de Datos para conseguir un buen rendimiento en los modelos que generan. Si no es así, las consecuencias pueden ser nocivas: modelos erróneos y decisiones incorrectas reforzadas por la sensación de confort y falsa confianza que nos aporta el uso de estas herramientas.
Conclusiones
• Los sistemas AutoML tienen la capacidad de modelar los problemas estándar de Ciencia de Datos con un buen rendimiento. La rapidez con la que procesan la información, entrenan los modelos y despliegan el servicio es de gran utilidad. No obstante, para implantar Machine Learning en una empresa hacen falta más recursos (básicamente personas expertas y tiempo).
• La importancia de la intervención humana en las tareas de definición del problema, preparación del conjunto de datos y, al finalizar, la toma de decisiones en función de las predicciones es crucial para un rendimiento satisfactorio en un proyecto ML.
• El elevado coste anual de las herramientas AutoML (50.000 – 200.000 €/año) sólo permite a las grandes empresas invertir en estas tecnologías. Además, es necesario asumir el coste adicional de tener una infraestructura de preparación de datos y un equipo técnico para exprimir al máximo estas herramientas.
• En muchas ocasiones, para proyectos estándar de ML es más inteligente comenzar con modelos sencillos que no necesitan de AutoML, fácilmente interpretables y, sobre todo, que hagan crecer al equipo de analítica de la organización en el camino hacia soluciones más complejas.


