
In recent years, Machine Learning is moving towards the use of models based on neural networks. With them, it has been possible both to improve the results in classic problems and to face new problems such as text analysis, image segmentation, or the classification of points clouds, among others. What makes these models so interesting is the possibility of creating prediction functions that can explain highly complex patterns in data and that, together with the backpropagation algorithm, allow those patterns to be learned easily.
To train this type of model, a high volume of data and great computational power are necessary, which is leading to deploying the solutions on servers where memory is not an issue. An example of this can be seen in the significance that is gaining in large companies to develop an ecosystem that allows managing all aspects of a project from the same space.
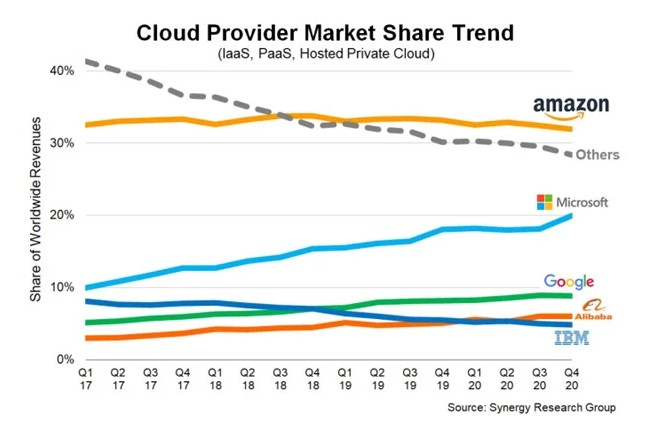
The main problem of having all the models centralized in an external server is the need to give access to the data from it. According to the General Data Protection Regulation (GDPR), the principles of data management should be:
- Data minimization: The collection and use of data should be the minimum necessary. “Personal data must be adequate, relevant and limited to what is necessary in relation to the purposes for which they are processed”. This is much more critical when it comes to images of people or confidential medical information.
- Storage limitations: The idea is to keep personal data for no longer than is necessary for the process for which it is required and to delete it subsequently. This principle potentially hinders the constant development of a cloud model, given that it is constantly improving, needs to maintain access to the data.
- Integrity and confidentiality: According to Article 5 GDPR “Personal data shall be processed in a manner that ensures appropriate security of the personal data, including protection against unauthorized or unlawful processing and against accidental loss, destruction, or damage, using appropriate technical or organizational measures (‘integrity and confidentiality’)”. This article is the only one that refers to data security but does not impose any specific measure since it is not possible to specify a security policy that can be used in any project and it is left to the discretion of the supplier.
In order to answer these security questions and given that it is not always possible to have sufficiently powerful servers or have access to enough data, it has been necessary to devise new ways of implementing these models.
In 2016, Google proposed in Communication Efficient Learning of Deep Networks from Decentralized Data a first example of decentralized Machine Learning models being the origin of federated learning. However, the term was not fully consolidated until the publication of Federated Learning: Collaborative Machine Learning without Centralized Training Data.
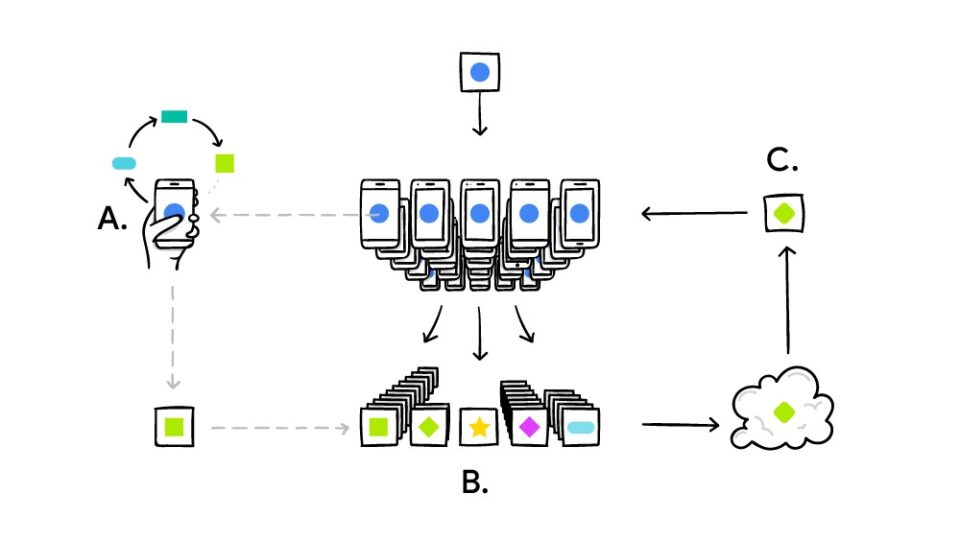
Horizontal Federated Learning
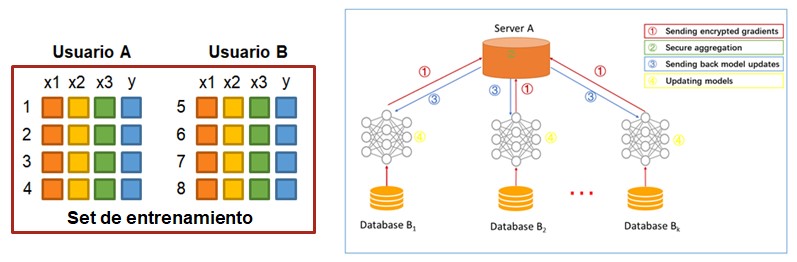
The general operation is as follows: The device downloads the updated model from the central server and trains the model using local data without sending anything to the server, that is, each device has a different batch of data. The only condition is that the data structure of each node/device/user is the same.
After the model has been updated, each device returns the changes in the encrypted coefficients to the central server, so that user data never leaves the devices. The central server combines all the individual models and updates the overall model which is sent back to the devices.
Currently, Google is implementing this system in Gboard for Android. Every time a user auto-completes a text, the information is saved locally, and when it is detected that the mobile phone is not in intensive use (for example, while charging at night), the information is analyzed and sent to the server in order to improve the following suggestions.
Another case where this method is also used is in automatic vehicle driving. In Deep Federated Learning for Autonomous Driving, a peer-to-peer structure is proposed which uses all user information without compromising privacy, and that also manages to slightly improve results compared to the state of the art in centralized models.
Vertical Federated Learning
The main difference compared to the horizontal one is that each node does not have all the information, that is, if the model has five features and one output, it may be that the first data source has three of those features and the other provides the output and the missing feature. Therefore, it is necessary to combine both to have all the necessary information to be able to execute the model.
An example of a real application would be the medical field, the specialist has concrete results of the tests, which would be the output of the classification model, and the primary medical center has the general history of the user, the features of the model. In order to make a prediction, the same identifier must be found in both databases.
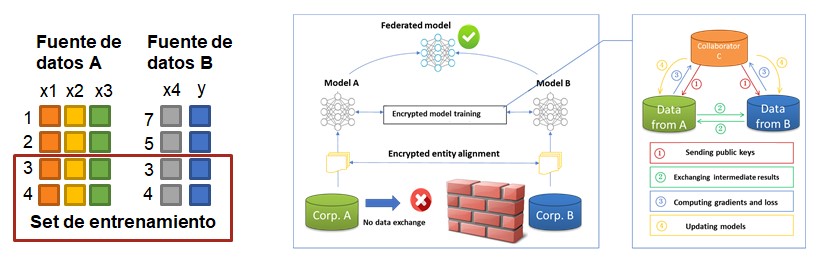
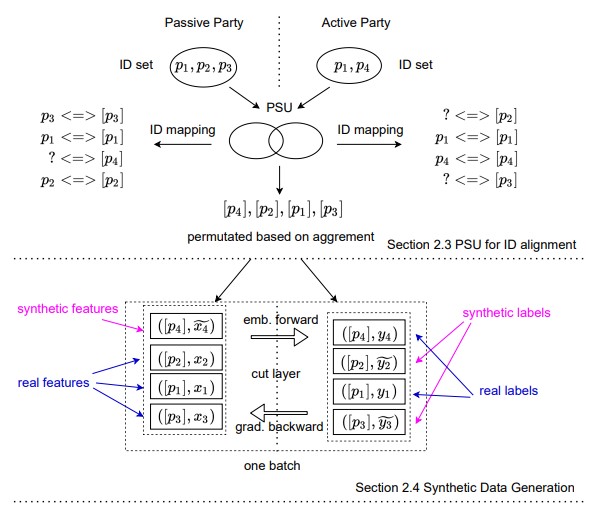
This information crossing is usually done through what is known as a Private Set Intersection, in which there is a personal identifier such as the ID card or the hashed email that allows crossing the records of both datasets and obtaining, as a result, those that both have in common. This results in each of the parts knowing whether each ID is part of the set of the other.
This is a serious problem if both sets of data are not managed by the same entity since it is possible to deduce whether it belongs to the other company or not. For an example of an insurer and a bank that share information, if the insurer had a risk model and crossed information with the bank, it would reveal which of its clients have an account at the bank and, therefore, it is getting more information than the bank, in theory, should make available to the insurer.
To avoid these leaks, Vertical Federated Learning without Revealing Intersection Membership uses an alternative method, known as Private Set Union, to train the model so that these privacy violations do not occur.
The idea is to combine all the records of the data sources instead of selecting those that appear in both, this has the problem that each source only has partial information about the features or the output is missing. To solve this, a probability function is modeled for each feature that returns the representative value based on the characteristics of the individuals (Differential Privacy), for example, payroll based on gender, age, and address. With these functions, it is now possible to fill in the missing information and train the model.
These techniques are still in the incipient stages of development and their use is not widespread across the board, with personal assistants such as Siri or Alexa still being their main market niche.
In the coming years, great development of these technologies is expected, which by taking advantage of the possibility of using data from different companies without losing their confidentiality, it will be possible to create models that are better prepared for the real world. One of the biggest areas that will benefit from this will be medicine, by being able to co-train models without having to share or centralize patient data. By being able to obtain more generalizable models by using a more variety of data, both insurance companies and banks could improve their fraud detection algorithms and reduce money laundering.
And this is just the beginning; For many industries and sectors, which currently do not have enough data on their own, federated learning could allow them to work together and create tools that could transform their operations using data from their IoT Edge devices among others.
