

What is AutoML? What tasks does it facilitate? What limitations does it have? Introduction to Automated Machine Learning technologies from the analysis of all phases of a Machine Learning project in production.
According to estimates made on the volume of data/information created, captured, copied, and consumed in the world, in the year 2025, the 180 zettabytes will be exceeded.
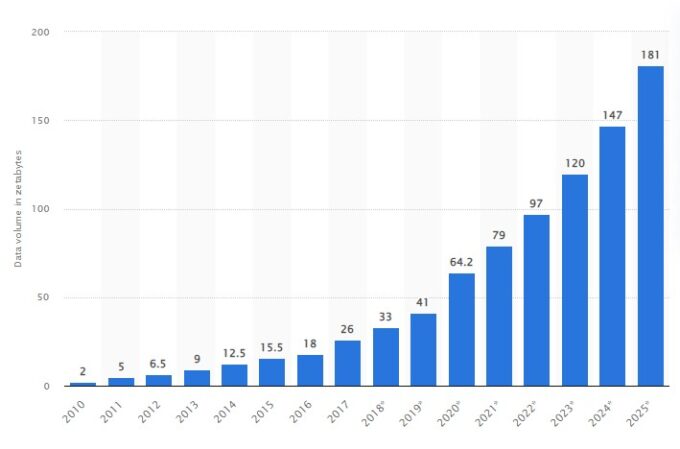
This increase in the amount of data, along with the high demand for Machine Learning (ML) projects, has been the definitive driver of the development of Machine Learning (AutoML) process automation tools.
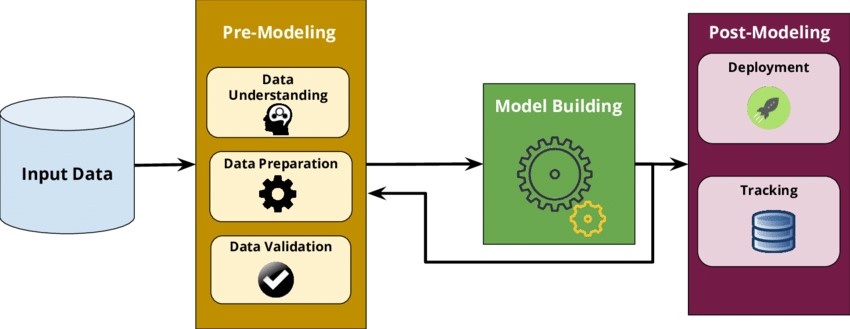
To fully understand what AutoML (Automated Machine Learning) consists of, it is necessary to know well the phases of a Machine Learning project put into production (see the figure below). The first phase includes understanding and preparing the data that is entered into the model. The second one is the construction of the model and the last phase is its deployment to make the predictions. This last phase must include a monitoring system that allows alarms to be triggered and continuous monitoring of the performance of the model.
AutoML (Automated Machine Learning) is a system, process or application that allows automatizing the entire process (end-to-end) of an ML project. The main goal of this automation is to eliminate human interaction from the whole process. These tools aspire to the ideal of uploading a data file, pressing a button and obtaining perfect results for the problem we intend to solve. The platform users only need to specify what they want to do, and the system must know how to compute it to obtain the best results. This objective is quite ambitious since it requires automating many processes requiring prior knowledge of the problem to be solved (even if ML is an adequate approach to that problem). The existing AutoML tools are still far from that goal: None of them is capable of automating all types of ML algorithms, these tools are better suited to solving standard Data Science problems (classification, regression, etc.) but they need to make a quality leap in unsupervised learning problems.
On many occasions, AutoML systems are confused with the process known as CASH (Combined Algorithm Selection and Hyperparameter Optimization), which consists of an optimization library of ML algorithms (it corresponds to the green box in the image above), capable of performing the following operations:
• Transformations.
• Imputation of missing values.
• Features selection.
• Selection of hyperparameters.
These types of tools are essential to developing good predictive models (Auto-WEKA is an example of a CASH library). An AutoML system, however, offers much more.
ML phases using an AutoML tool
Before starting an ML project, it is necessary to answer three questions:
- What problem do you want to solve?
- What do you want to achieve with the solution?
- Is ML necessary to solve it?
These questions are crucial before starting any ML project since many problems can be solved with good data analysis, statistical solutions, or actually, they are optimization problems (prescriptive analytics, and not predictive).
Once the problem has been confirmed as a solvable problem with ML, data is needed. It is required to identify what data is needed (it is relevant to the problem and it needs knowledge of the business), and how it will be obtained to feed the models. It will be essential to resolve access to information systems that are not always easy to integrate, or to external sources, often with incomplete data or not prepared for the goal of our ML project. This step is usually very time consuming for the deployment. At least it will require several ETL processes, of varying complexity.
The following image shows the flow of an ML project in production using an AutoML system. As described above, in the two initial steps, the intervention of an expert is necessary who interprets the problem well and can clean and process the data that allow the modelling of the problem, a task that is beyond the scope of the systems by AutoML.
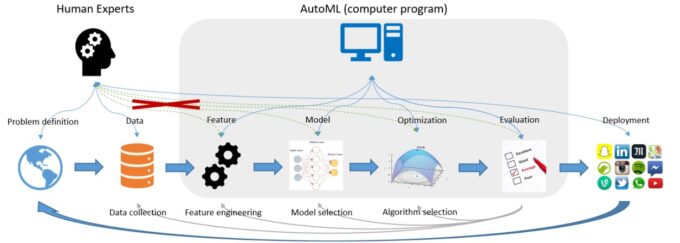
Only a few AutoML tools (for example, DataRobot, H20 Driverless AI) perform the task known as feature engineering, which consists of using the knowledge of the field to select and transform the most relevant features from the raw data before building the predictive model. Therefore, knowledge of the problem provided by an expert in the domain is necessary to fine-tune the results based on the use case. In this phase of the process, the expert contribution is much more remarkable when the input data is more complex than simple tabular data (for example, natural language text, images, etc.), something relatively common in many scenarios.
Once the data has been prepared, the AutoML system launches the model training, just pressing a button, many models can be trained in parallel in the cloud or on the on-premise server available. After completing the models training, the AutoML tools evaluate them and allow the intervention of the expert user to choose the best model to deploy. AutoML tools have a large collection of model types to apply, and in most cases, the best results are obtained with more complex models. These models are often hard to interpret (although these tools partially facilitate that interpretation), they require a lot of computational time to be trained and to make predictions, and they are also difficult to maintain without the support of Data Science experts.
When the model has been selected, it is time to deploy it to be accessible from different business processes. AutoML tools allow this deployment of the models to obtain predictions and, in addition, they have a monitoring system of the deployed models to track and analyze their performance.
Finally, we must not forget the most valuable part of the entire ML process: decision making based on the data obtained. For this part, some AutoML tools add value, but again human intervention is necessary to define rules that adapt to the performance of the model.
In short, AutoML tools greatly facilitate this type of task and have good practice guides that, when correctly applied, considerably reduce the development time of these projects, but it is necessary to have a broad knowledge of the problem and Data Science to achieve a good performance in the models they generate. Otherwise, the consequences can be harmful: wrong models and wrong decisions reinforced by the feeling of comfort and false confidence that the use of these tools gives us.
Conclusions
• AutoML systems are capable of modelling standard Data Science problems with good performance. The speed with which they process the information, train the models and deploy the service is very useful. However, to implement Machine Learning in a company more resources are needed (basically experts and time).
• The importance of human intervention in the tasks of defining the problem, preparing the data set, and eventually making decisions based on predictions is crucial for successful performance in an ML project.
• The high annual cost of AutoML tools (50,000€ – 200,000€ / year) only allows large companies to invest in these technologies. In addition, it is necessary to assume the additional cost of having a data preparation infrastructure and a technical team to make the most of these tools.
• In many cases, for standard ML projects it is smarter to start with simple models that do not need AutoML, are easily interpretable and, above all, that grow the organization’s analytics team on the way to more complex solutions.


