

Can Artificial Intelligence write a blog? Why has Natural Language Processing grown so much? What are its uses?
We can think of no better way to start this article than to let artificial intelligence itself write its introduction. To do so, let’s give it a few words to define the subject:
[Escrito por un ser humano ->]The post, in this case, is going to be about natural language processing (NLP).
And let’s be amazed at what the algorithms return:
[Primeros párrafos propuestos por las tecnologías que vamos a presentar aquí ->]: “Natural Language Processing (NLP) is a branch of Artificial Intelligence dedicated to the study of how humans process the information that comes to us through language. It is a very complex area of research, as language is a very powerful tool for communicating and transmitting the information.
Natural Language Processing systems try to emulate the way humans process information, eg. they strive to analyse the meaning of words and construct a representation of the world that allows us to interpret language naturally.
Advances in this field of Artificial Intelligence have made it possible to develop systems that are capable of understanding language in a relatively natural way, which is…”
All of the above has been written by an Artificial Intelligence, specifically a language model called GPT-3, from OpenAI. If you were surprised, and we are sure you were, we would like to use this article to contextualise these technologies and suggest some of their main applications.
Language Models
The last few years have seen a real revolution in this field of Artificial Intelligence, of which data science, predictive analytics and computational linguistics constitute its pillars. One of the main reasons for its take-off is the application of Deep Learningtechniques, in particular neural networks with architectures based on Transformers(those used by GPT-3 or BERT), which have revolutionised traditional language models.
These models, which initially were not much more than probabilistic analysis of the successive occurrence of different words in a language, have evolved into impressive neural networks spanning more than 175 billion parameters (in the case of GPT-3) and have demonstrated amazing capabilities to understand and emulate human language. In order for this kind of models to perform so well, they are usually trained on huge amounts of documents (called corpus) so that they are able to predict the words that could extend a text and even perform linguistic tasks or address topics that are not contained in the set of texts they have been trained on.
We are not going to delve into the technology behind it, which would be beyond the scope of a blog like this one, but we will point out that, when one starts with this hybrid of language and mathematics, there are approaches that, even from a non-technical perspective, are truly fascinating. As an example:
- Word embeddings, the words of a vocabulary transformed into vectors, are often one of the first stages of the neural network behind any modern language model.
These embeddingsare built on a very basic principle: that the meaning of a word is directly related to the words that appear around it in the texts. Thus constructed, one discovers how simple operations with these word-vectors, generated without any knowledge of the language, give semantically reasonable results (e.g. the classic “king + woman = queen”).
- Los modelos de atención, verdadera esencia de la arquitectura transformer , son los componentes que hacen posible que la red neuronal aprenda un hecho esencial del lenguaje: que en los textos las palabras se referencian unas a otras a distancias que pueden ser muy variables (ej. en “la casa” hay una concordancia de género en palabras adyacentes, pero en “Juan fue a su casa” “Juan” y “su” tienen una relación evidente sin estar situadas una al lado de la otra).
For readers with a passion for the subject, we would like to recommend the essential “Speechand Language Processing, by Dan Jurafsky and James H. Martin”, available at stanford.edu.
Beyond the models, architectures or algorithms behind Natural Language Processing, it is particularly interesting to analyse the many challenges that these techniques can address from a business point of view.
Business Applications
SENTIMENT ANALYSIS – SOCIAL MEDIA MONITORING
Through different techniques or pre-trained models, it is possible to carry out the analysis of social media texts, reviews or other kinds of comments created by users on websites, and extract valuable information. For example, whether such comments are positive or negative, or whether they are subjective or objective.
This allows us to detect negative news or comments to handle, mitigate or remedy them in customer service. Similarly, the analysis of these evaluations would lead to conclusions about the customer’s opinion of the service or product, so that better decisions can then be made based on the customer’s preferences or expectations.
Another interesting business case is supplier assessment. Companies will be able to automate the collection and evaluation of a large amount of relevant information about potential suppliers before starting to work with them.
CHATBOTS
Advances in NLP make customer service, through bots, more accurate and satisfying. With GPT-3, we can deploy bots that have really deep intelligence, as they do notrespond with stored phrases in the form of a decision tree but generate almost human-like text in the interaction with the user.
TEXT SUMMARY
In order to reduce synthesis time, these techniques can be used to summarise very long texts in which the main themes and ideas of them are identified and presented concisely.
It currently comes in two modes: extractive and abstractive. The extractive type of summary focuses on highlighting the most relevant sentences or paragraphs of the text, while the abstractive summary generates new text based on the most important concepts.
TEXT CLASSIFICATION
Using Natural Language Processing and supervised learning techniques, texts or audio transcripts can be categorised in order to globally or sectionally label the topics they refer to, achieving a precise segmentation of categories in each of the portions of an unstructured text.
MARKET ANALYSIS – MARKET INTELLIGENCE
The application of NLPcombined with web scraping techniques makes it possible to track market and competitor evolution, uncovering trends, unmet demands and possible competitor movements.
On the other hand, image campaigns to build, reinforce and improve public appreciation of a brand, product or service can be designed and fine-tuned more effectively if we simultaneously evaluate, through NLP, the impact of such actions on the texts generated by the target audience of these campaigns.
SURVEY ANALYSIS – FEEDBACK ANALYSIS
The possibility of giving feedbackon a product or service after use or consumption is becoming more and more common. Given the enormous volume of data, only automated analysis using Natural Language Processing techniques will make it possible to extract valuable conclusions to improve subsequent decisions regarding these products or services.
In addition to these cases and applications, NLP has improved multiple solutions directly related to language, such as text translation, handwritten text recognition, grammar and spelling correction, or text or word prediction.
There is no doubt that Natural Language Processing will be a very relevant field of Artificial Intelligence in the coming years. In fact, if we search “dimensions.ai”, a database of scientific publications, we can observe the increase in the number of articles containing the acronym “NLP”:
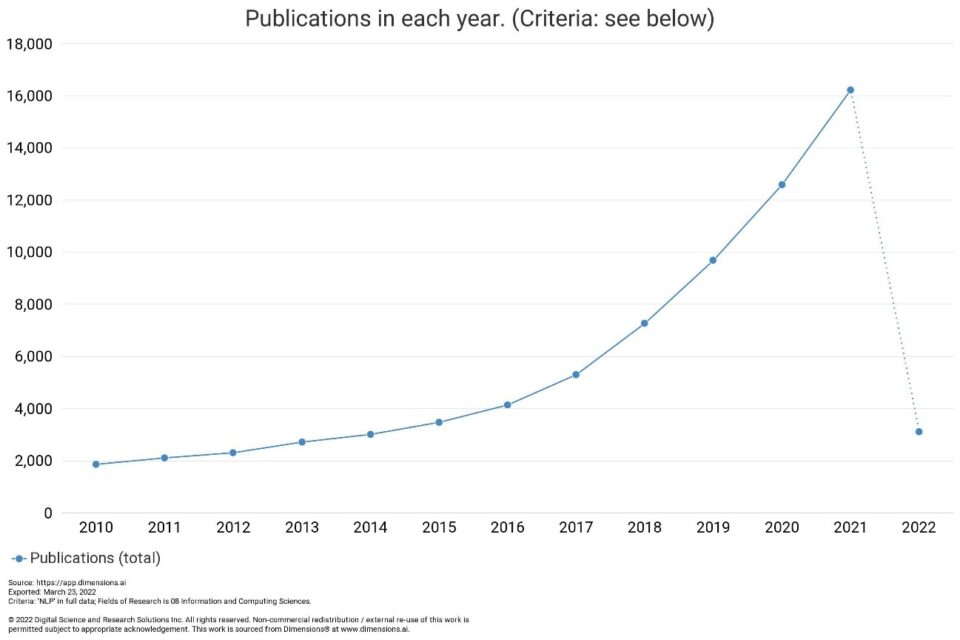
In short, the content of linguistic interactions (text, voice, etc.) will be a valuable source of information for business in the future, and interaction with artificial intelligence will become more and more common, just as we are starting to interact with virtual assistants in our daily lives.
Who knows, will the day come when this blog is written entirely by Artificial Intelligence? Moreover, are you sure that this text you have just read has not been written by a machine?


