

Inspirados por los concursos de kaggle y varios eventos similares, hace algunos meses decidimos llevar a cabo un hackathon interno en baobab.
Para quien no esté familiarizado con el término, un hackathon (combinación de “hack” y “maratón”) es un encuentro en el que varios grupos compiten de manera prácticamente continua por resolver un problema previamente definido. Es un evento centrado en un reto concreto que fomenta el pensamiento creativo y el trabajo en equipo y del que suelen surgir soluciones extraordinariamente innovadoras.
Para nuestro hackathon decidimos competir por resolver de la manera más eficiente un problema combinatorio. Ocho personas se aventuraron a participar. El evento duró oficialmente dos tardes de viernes aunque al final extendimos el plazo de entrega para dar tiempo a los equipos a pulir la solución y hacer un benchmark unificado. Para facilitar la comparación decidimos (después de un poco de negociación) hacer todos los desarrollos en python.
El problema
Decidimos dedicar el hackathon a resolver una variante de un problema clásico de secuenciamiento (scheduling) de tareas. Partíamos de un conjunto de tareas no interrumpibles que debían realizarse. Algunas de las tareas tienen precedencia sobre otras. Por ejemplo si la tarea A tiene precedencia sobre la tarea B, la tarea A debe acabar antes de que la tarea B empiece.
A su vez, hay dos tipos de recursos. Los recursos renovables son consumidos en cada periodo en el que la tarea se realiza y la capacidad de éstos se recupera al inicio de cada nuevo periodo. Los recursos no-renovables se consumen solo una vez por tarea y no se recuperan nunca.
Finalmente, cada tarea tiene distintos “modos” en que puede ser realizada. En función del modo, la duración de la tarea y su consumo de recursos variará.
El objetivo es encontrar la planificación que, eligiendo el modo y el periodo de inicio para cada tarea, emplee el menor número posible de periodos, sin gastar más recursos de los disponibles.
La tabla siguiente presenta los datos de entrada de una instancia para las primeras 5 tareas de las 18 totales. Para cada tarea (Job) y cada modo (Mode) se tiene la duración y el consumo de cuatro recursos: “R 1” y “R 2” son renovables, “N 1” y “N 2” son no-renovables. Entre paréntesis se tienen las capacidades de cada recurso. La columna “Dependencies” muestra las otras tareas que tienen que terminar antes de iniciar la actual (por ejemplo: la tarea 1 tiene precedencia sobre la tarea 2, 3 y 4).
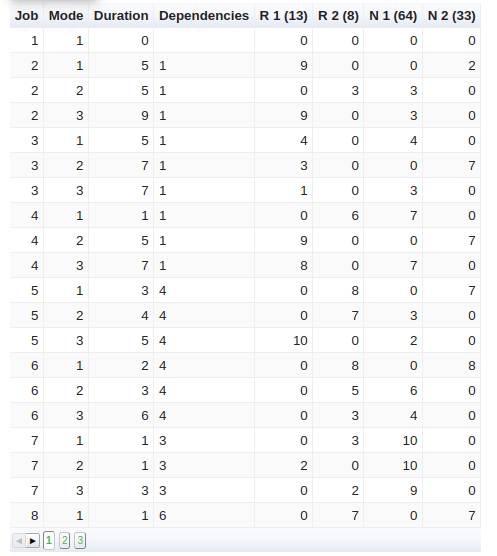
Para esta competición empleamos aproximadamente sesenta instancias diferentes similares a esta.
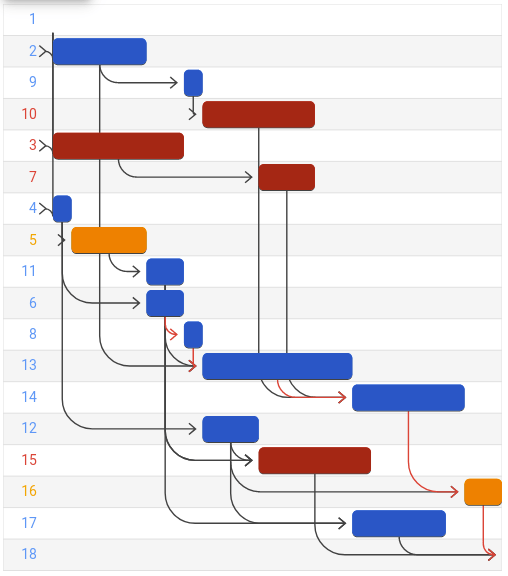
La figura siguiente muestra la solución óptima a esta instancia en un diagrama de Gantt. Cada fila es una tarea y el color indica el modo en que se realizó la tarea (azul: 1, naranja: 2, rojo: 3). Las flechas negras representan las relaciones de dependencia entre las tareas.
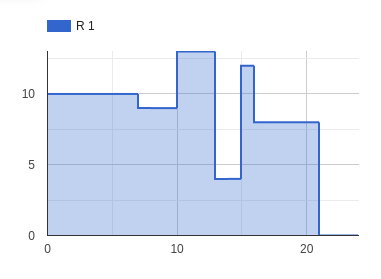
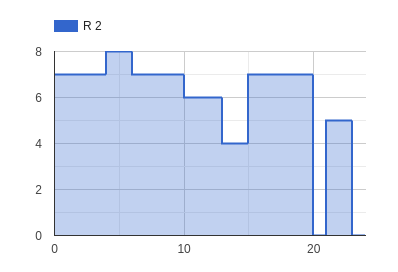
Se puede comprobar que no se han utilizado más recursos renovables de los disponibles con las siguientes gráficas, que muestran que el uso máximo de los recursos “R 1” y “R 2” alcanzó 13 y 8, respectivamente, lo cual cae dentro de lo aceptable.
 |  |
La metodología
La metodología fue la siguiente:
- Creamos un repositorio público (y al que por lo tanto puedes acceder): https://github.com/baobabsoluciones/hackathonbaobab2020
- Dimos como partida un código base en python que permite leer los datos de entrada, generar ficheros de salida con la solución y hacer comprobaciones de una solución.
- Hicimos un algoritmo de ejemplo que generaba una solución (rápida y no óptima) al cual llamamos “default”.
- Diseñamos algunas pruebas unitarias para validar que cada método de solución funcionaba correctamente.
- Cada equipo entregó su solución mediante un Pull Request.
- Para los resultados, utilizamos un set de sesenta instancias aleatorias.
Técnicas
Tres grupos desarrollaron y entregaron un método de resolución. En baobab tenemos una formación bastante más fuerte en modelos de programación lineal y por ello dos grupos eligieron técnicas basadas en MIP (Mixed Integer Programming). A pesar de la falta de experiencia en ello, un grupo se aventuró a probar un paradigma distinto: la programación por restricciones (CP por sus siglas en inglés).
Aunque no era una condición, todos los modelos fueron probados exclusivamente con solvers de código abierto.
La tabla siguiente resume cada una de las técnicas comparadas más adelante. Para más detalle, se puede ver el repositorio de github.
| Nombre | Técnica | Descripción |
| default | Heurístico de ejemplo | Las tareas se eligen una por una respetando las dependencias y nunca haciendo más de una tarea en paralelo. |
| ortools | CP | Modelo puro de programación por restricciones. Solver: CP-SAT. |
| Iterator_HL | MIP + heurístico | Descomposición heurística en modelos MIP. Solver: CBC. |
| loop_EJ | MIP + heurístico | Descomposición heurística en modelos MIP. Solver: CBC. |
Resultados
La eficiencia de un método de resolución se puede medir de muchas maneras. La más inmediata es a partir de la calidad de la solución después de un tiempo límite. La calidad de la solución en este caso se puede medir de dos formas: en qué medida fueron cumplidos los requisitos (precedencia, utilización de recursos, etc.) y cuánto se cumplió con el objetivo (es decir: el número de periodos requerido por la planificación para ejecutar todas las tareas). Además, para métodos exactos como los utilizados en esta competición, se mide también el tiempo en probar que una solución es óptima.
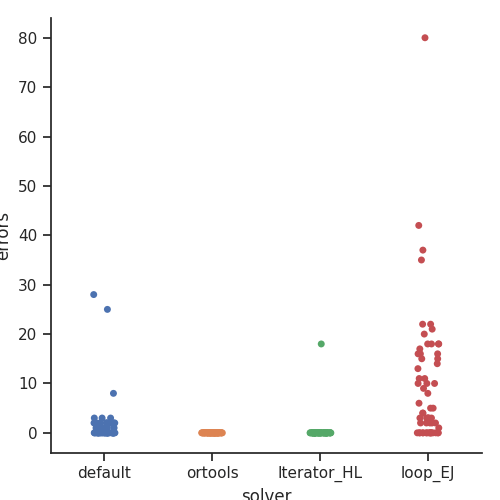
Empecemos por el cumplimiento de los requisitos: la siguiente gráfica muestra el número de “errores” en las soluciones entregadas por cada método. Cada “error” es un incumplimiento de un requisito. La gráfica muestra dos técnicas que devuelven soluciones factibles: “ortools” e “Iterator_HL”. “Default” y “loop_EJ” devolvieron soluciones no factibles para un gran número de instancias, con lo que quedaron ya prácticamente descartadas.
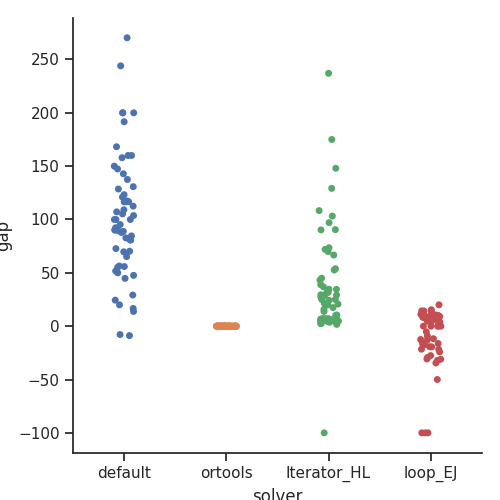
Con respecto a la segunda medida de calidad: el tiempo total de planificación de tareas, la siguiente gráfica muestra una comparación relativa de la calidad de la instancia. Para ello usamos como referencia la técnica “ortools”, al ser la que dio soluciones con menos errores (ninguno). La técnica “loop_EJ” y la técnica “default” devolvieron planificaciones más cortas en algunas instancias, pero los resultados no fueron válidos por la cantidad de errores que contenían.
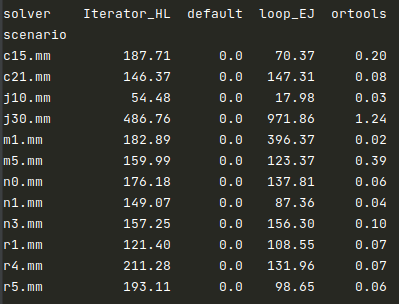
Finalmente, la tabla siguiente muestra las medias en tiempos de resolución para cada técnica y cada escenario (cada escenario contiene cinco instancias). Las dos técnicas basadas en MIP (“Iterator_HL” y ”loop_EJ”) tuvieron duraciones mucho más elevadas. En particular para las instancias más grandes (j30.mm). “ortools” no tuvo problemas de tiempo.
El claro ganador de este hackathon fue “ortools”. En cualquier métrica (tiempo, calidad de solución) resultó ser el mejor muchas veces por órdenes de magnitud.
Conclusión
Los plazos y prisas de un proyecto real hacen que no tomemos tiempo para probar nuevas técnicas y compararlas rigurosamente con las que ya conocemos. Es por eso que este hackathon (y los futuros) suelen ser momentos muy útiles de exploración e innovación. En particular, nunca antes habíamos trabajado con la librería “ortools” ni con el solver CP-SAT y fue una muy grata sorpresa comprobar que, para problemas de scheduling “puro”, este solver de código abierto funciona muy bien.
Con todo, quedan todavía otras muchas técnicas interesantes por probar con este problema. Por ejemplo, la programación dinámica y metaheurísticos. ¿Te animas a proponer e implementar una nueva técnica? Solo hace falta clonar el repositorio público, seguir las instrucciones para añadir un nuevo método y hacer un Pull Request para que la añadamos al benchmark.
Ahí queda el reto.


