
En los últimos años, el Machine Learning se está dirigiendo hacia el uso de modelos basados en redes neuronales. Con ellas ha sido posible tanto mejorar los resultados en problemas clásicos como afrontar nuevos problemas como el análisis de textos, segmentación de imágenes o la clasificación de nubes de puntos entre otros. Lo que hace tan interesantes estos modelos es la posibilidad de crear funciones de predicción que puedan explicar patrones muy complejos en los datos y que, junto al algoritmo de backpropagation, permitan aprender esos patrones de manera sencilla.
Para entrenar este tipo de modelos es necesario un elevado volumen de datos y una gran potencia computacional, lo que está llevando a desplegar las soluciones en servidores donde la memoria no sea un problema. Un ejemplo de esto se puede ver en la importancia que está cobrando en las grandes compañías desarrollar un ecosistema que permita gestionar todos los aspectos de un proyecto desde un mismo espacio.
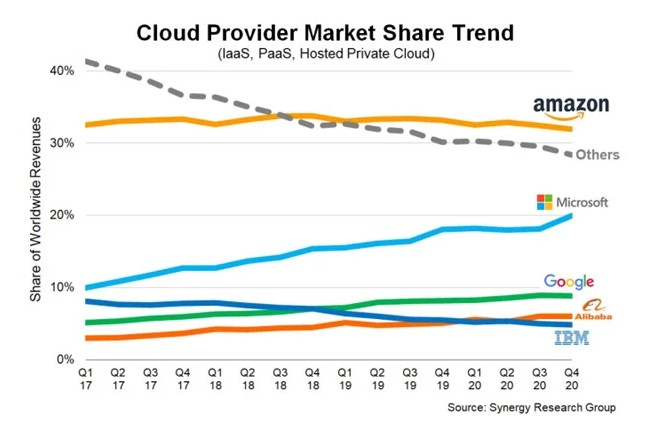
El principal problema de tener todos los modelos centralizados en un servidor externo es la necesidad de dar acceso a los datos desde el mismo. Según el General Data Protection Regulation (GDPR) los principios de la gestión de datos deberían ser:
- Minimización de datos: la recopilación y uso de los datos debe ser el mínimo necesario. “Los datos personales deben ser adecuados, relevantes y limitados a lo que sea necesario en relación con los fines para los que se procesan”. Esto es mucho más crítico cuando se trata de imágenes de personas o de información médica confidencial.
- Limitaciones de almacenamiento: la idea es mantener los datos personales el tiempo estrictamente necesario para el proceso para el que se requieran y borrarlos posteriormente. Este principio dificulta potencialmente el desarrollo constante de un modelo en la nube, ya que al estar siempre en constante mejora necesita mantener el acceso a los datos.
- Integridad y confidencialidad: según el artículo 5 del GDPR “Personal data shall be processed in a manner that ensures appropriate security of the personal data, including protection against unauthorised or unlawful processing and against accidental loss, destruction or damage, using appropriate technical or organisational measures (‘integrity and confidentiality’)”. Este artículo es el único que se refiere a la seguridad de los datos, pero no impone ninguna medida concreta, ya que no es posible especificar una política de seguridad que se pueda emplear en cualquier proyecto y lo deja al criterio del proveedor.
Para responder a estas cuestiones de seguridad y dado que no siempre es posible disponer de unos servidores suficientemente potentes ni tener acceso a bastantes datos, ha sido necesario idear nuevas formas de implementar estos modelos.
En 2016, Google propuso en Communication Efficient Learning of Deep Networks from Decentralized Data un primer ejemplo de modelos de Machine Learning descentralizados, siendo esto el origen del aprendizaje federado, aunque el término no se termina de consolidar hasta la publicación de Federated Learning: Collaborative Machine Learning without Centralized Training Data.
Aprendizaje federado horizontal
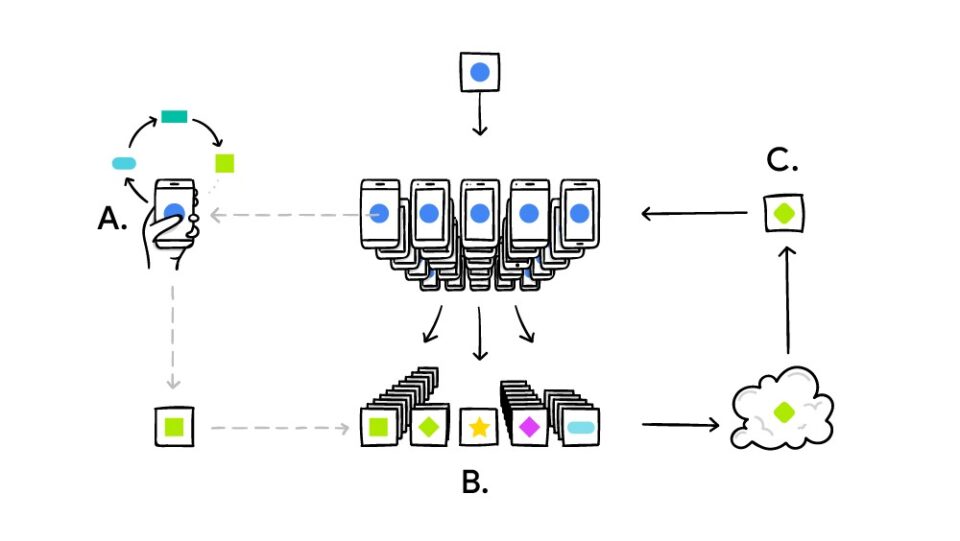
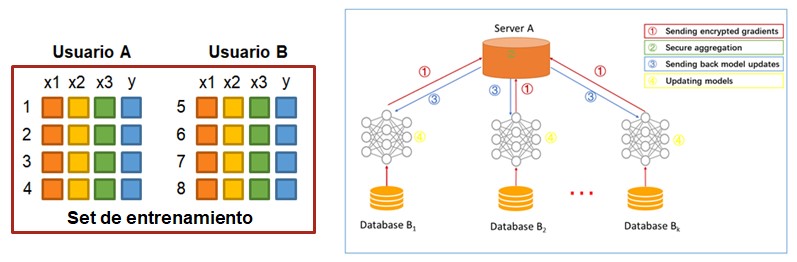
El funcionamiento general es el siguiente: el dispositivo descarga del servidor central el modelo actualizado y entrena el modelo utilizando los datos locales sin enviar nada al servidor, es decir, cada dispositivo cuenta con un batch de datos diferente. La única condición es que la estructura de los datos de cada nodo/dispositivo/usuario sea la misma.
Una vez se ha actualizado el modelo, cada dispositivo devuelve al servidor central los cambios en los coeficientes encriptados, de forma que los datos de los usuarios nunca salen de los dispositivos. El servidor central combina todos los modelos individuales y actualiza el modelo general que vuelve a ser enviado a los dispositivos.
Actualmente Google está implementando este sistema en Gboard para Android. Cada vez que un usuario autocompleta un texto se guarda localmente la información y cuando se detecta que el móvil no está en uso intensivo (por ejemplo, mientras se carga por la noche), se analiza la información y se envía al servidor para mejorar las siguientes sugerencias.
Otro caso en el que también se utiliza este método es en la conducción automática de vehículos. En Deep Federated Learning for Autonomous Driving se propone una estructura peer-to-peer que utiliza toda la información de los usuarios sin comprometer la privacidad, y que además consigue mejorar ligeramente los resultados frente el estado del arte en modelos centralizados.
Aprendizaje federado vertical
La principal diferencia frente al horizontal es que cada nodo no dispone de toda la información, es decir, si el modelo cuenta con cinco features y un output puede ser que la primera fuente de datos tenga tres de esas features y la otra aporte el output y la feature faltante. Por lo tanto hace falta combinar ambas para tener toda la información necesaria para poder ejecutar el modelo.
Un ejemplo de aplicación real sería el ámbito médico, el especialista cuenta con resultados concretos de las pruebas, lo que sería el output del modelo de clasificación, y el centro de medicina primaria cuenta con el histórico general del usuario, las features del modelo. Para poder realizar una predicción es necesario que el mismo identificador se encuentre en ambas bases de datos.
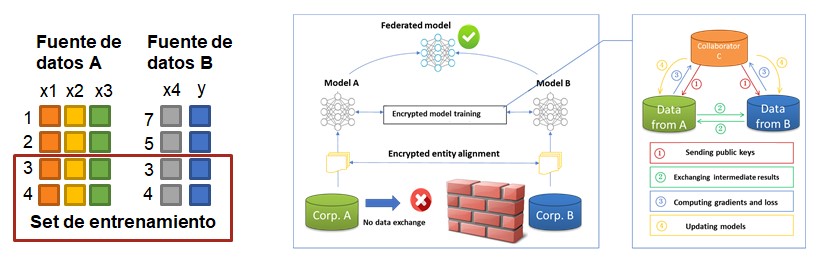
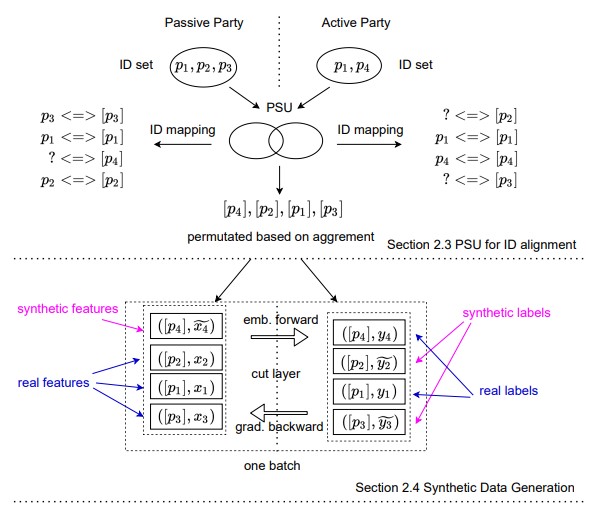
Este cruce de información se suele hacer mediante lo que se conoce como un Private Set Intersection, en el que existe un identificador personal como el DNI o el email hasheado que permite cruzar los registros de ambos datasets y obtener como resultado los que tienen en común ambos. Esto resulta en que cada una de las partes conoce si cada ID forma parte del conjunto o no del otro.
Esto es un problema grave si ambos conjuntos de datos no están gestionados por una misma entidad, ya que es posible inferir si pertenece o no a la otra compañía. Para un ejemplo de una aseguradora y un banco que compartan información, si la aseguradora tuviese un modelo de riesgo y cruzara información con el banco quedaría al descubierto cuáles de sus clientes tienen cuenta en el banco y, por lo tanto, está consiguiendo más información de la que el banco, en principio, debería poner a su disposición.
Para evitar estas filtraciones, en Vertical Federated Learning without Revealing Intersection Membership se utiliza un método alternativo, conocido como Private Set Union, para entrenar modelo y que no se produzcan estas violaciones de la privacidad.
La idea es combinar todos los registros de las fuentes de datos en vez de seleccionar los que aparezcan en ambas, esto tiene el problema de que cada fuente solo tiene información parcial de las features o le falta el output. Para solventarlo, se modela una función de probabilidad de cada feature que devuelva el valor representativo en base a las características de los individuos (Differential Privacy), por ejemplo, la nómina en función del género, edad y domicilio. Con estas funciones ya es posible completar la información faltante y entrenar el modelo.
Estas técnicas todavía se encuentran en etapas incipientes de desarrollo y su utilización no está extendida en todos los ámbitos, siendo todavía su nicho de mercado principal los asistentes personales como Siri o Alexa.
En los próximos años se espera un gran desarrollo de estas tecnologías, que aprovechando la posibilidad de utilizar datos de diferentes empresas sin perder la confidencialidad en los mismos, se podrán crear modelos que estén mejor preparados para el mundo real. Una de las mayores áreas que se beneficiará de esto será la medicina, al poder entrenar de forma conjunta modelos sin tener que compartir o centralizar los datos de los pacientes. Al poder obtener modelos más generalizables por utilizar más variedad de datos tanto las compañías de seguros como los bancos podrían mejorar sus algoritmos de detección del fraude y reducir el blanqueo de dinero.
Y esto es solo el comienzo; a muchas industrias y sectores, que actualmente no tienen datos suficientes por si solos, el aprendizaje federado podría permitirles trabajar juntas y crear herramientas que podrían transformar sus operaciones utilizando datos de sus dispositivos IoT Edge entre otros.


